Flink源码解析[Source](二) - 如何创建Flink kafka source
概述
本系列文章是旨在熟悉摸头flink的source-connect原理,希望可以做到自己可以实现一个新的source,代码解析将会以kafka的实现配合flink的api为主线解析。
flink版本为1.12.0
第一篇:为什么要解析Source源码
第二篇:如何创建Flink kafka source
第三篇:新版Data Srouces详解&源码
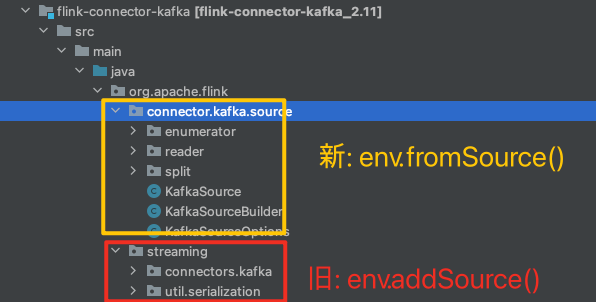
创建Source的两种方式
创建source两种方式
- env.addSource: 1.11.0版本之前的方式,现在普遍使用的方式。
- env.fromSource: 1.11.0之后的方式,抽象的更好。
由于新版本api还没有普遍使用,一般实现一个source-connect会实现这两种api,例如flink的仓库当中kafka的实现分为两个package,这两个package之间代码是互相独立的。

下面分别介绍两种方式的用法和简要原理
第一种使用方式 - addSource
使用addSource创建Source时,需要定义个SourceFunction的实现,例如下面使用kafka的source实现。
1
2
3
4
5
6
7
8
9
| DataStream<ClickEvent> clicks =
env.addSource(new FlinkKafkaConsumer<>(inputTopic, new ClickEventDeserializationSchema(), kafkaProps))
.name("ClickEvent Source")
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<ClickEvent>(Time.of(200, TimeUnit.MILLISECONDS)) {
@Override
public long extractTimestamp(final ClickEvent element) {
return element.getTimestamp().getTime();
}
});
|
在StreamExecutionEnvironment方法内部,实际是包装了一个StreamSource传给DataStreamSource最终创建了一个LegacySourceTransformation。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| private <OUT> DataStreamSource<OUT> addSource(
final SourceFunction<OUT> function,
final String sourceName,
@Nullable final TypeInformation<OUT> typeInfo,
final Boundedness boundedness) {
checkNotNull(function);
checkNotNull(sourceName);
checkNotNull(boundedness);
TypeInformation<OUT> resolvedTypeInfo = getTypeInfo(function, sourceName, SourceFunction.class, typeInfo);
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function);
return new DataStreamSource<>(this, resolvedTypeInfo, sourceOperator, isParallel, sourceName, boundedness);
}
|
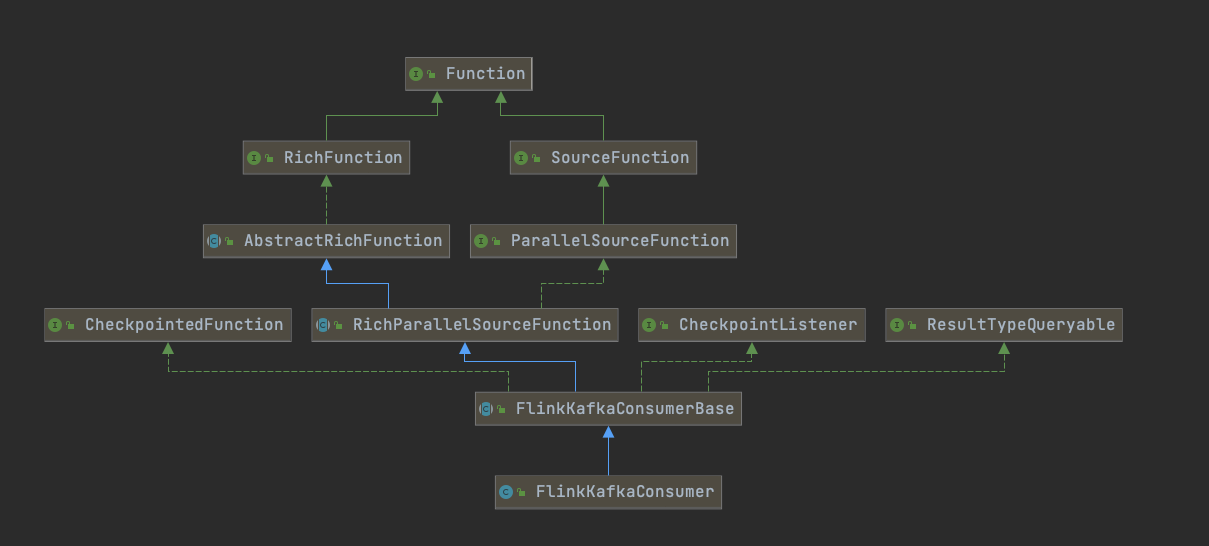
对于kafka的SourceFunction的实现参考下面类图,核心类在于FlinkKafkaConsumerBase。
在创建Source时可以根据需要设置watermark,关于watermark请参考官网文档1.12.0。例如下面使用样例,提取kafka中消息的time为eventTime。
1
2
3
4
5
6
7
8
9
| DataStream<ClickEvent> clicks =
env.addSource(new FlinkKafkaConsumer<>(inputTopic, new ClickEventDeserializationSchema(), kafkaProps))
.name("ClickEvent Source")
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<ClickEvent>(Time.of(200, TimeUnit.MILLISECONDS)) {
@Override
public long extractTimestamp(final ClickEvent element) {
return element.getTimestamp().getTime();
}
});
|
实际上设置watermark时flink包装了在创建kafka的source时生成的LegacySourceTransformation,有点像装饰者模式。Transformation应该代表了job的逻辑有向无环图,这块还没有仔细研究,推荐阅读:浅谈 Flink - Transformations
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(
WatermarkStrategy<T> watermarkStrategy) {
final WatermarkStrategy<T> cleanedStrategy = clean(watermarkStrategy);
final int inputParallelism = getTransformation().getParallelism();
final TimestampsAndWatermarksTransformation<T> transformation =
new TimestampsAndWatermarksTransformation<>(
"Timestamps/Watermarks",
inputParallelism,
getTransformation(),
cleanedStrategy);
getExecutionEnvironment().addOperator(transformation);
return new SingleOutputStreamOperator<>(getExecutionEnvironment(), transformation);
}
|
关于1.11.0版本之前的api,在自定一个Source时需要涉及几块知识:
- watermark是如何和source结合的。
- checkpoint是如何和source结合的。
- source中的实现是如何分部在jobManager和taskManager中的。
这块笔者写笔记时还没有深入研究,先TODO起来,感兴趣的参考文章:
官方文档DataStream Connectors
Flink kafka source & sink 源码解析
第二种使用方式 - fromSource
该方式是在flink1.11.0之后提供的新版本api,抽象性更好,和第一种source一样,最终也是创建了一个DataStreamSource对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| KafkaSource<PartitionAndValue> source = KafkaSource
.<PartitionAndValue>builder()
.setBootstrapServers(KafkaSourceTestEnv.brokerConnectionStrings)
.setGroupId("testBasicRead")
.setTopics(Arrays.asList(TOPIC1, TOPIC2))
.setDeserializer(new TestingKafkaRecordDeserializer())
.setStartingOffsets(OffsetsInitializer.earliest())
.setBounded(OffsetsInitializer.latest())
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<PartitionAndValue> stream = env.fromSource(
source,
WatermarkStrategy.noWatermarks(),
"testBasicRead");
|
fromSource的创建主要是直接生成一个Source的实现,Source是一个build设计方式的接口,主要是生成如下几个重要对象:
- Source
- SplitEnumerator
- Split
- SourceReader
其实关于这种Source的创建方式,在官网中有一个专门的章节在介绍:官网data source,其中还介绍了这种方式是如何扩展的,包括kafka,pusar都按这种api实现了对应的扩展。
对于fromSource的方式,我在另外一篇文章中会详细解读官网介绍,并加上自己的理解说明:新版Data Srouces详解&源码
两种创建方式分析
无论是上面哪一种方式创建的Source,最终flink会创建一个:DataStreamSource
不同点是传入的Transformation实现不同
对于addSource的方式传入的是:LegacySourceTransformation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public DataStreamSource(
StreamExecutionEnvironment environment,
TypeInformation<T> outTypeInfo,
StreamSource<T, ?> operator,
boolean isParallel,
String sourceName,
Boundedness boundedness) {
super(environment, new LegacySourceTransformation<>(sourceName, operator, outTypeInfo, environment.getParallelism(), boundedness));
this.isParallel = isParallel;
if (!isParallel) {
setParallelism(1);
}
}
|
对于fromSource的方式传入的是:SourceTransformation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public DataStreamSource(
StreamExecutionEnvironment environment,
Source<T, ?, ?> source,
WatermarkStrategy<T> watermarkStrategy,
TypeInformation<T> outTypeInfo,
String sourceName) {
super(environment,
new SourceTransformation<>(
sourceName,
source,
watermarkStrategy,
outTypeInfo,
environment.getParallelism()));
this.isParallel = true;
}
|
参考资料
- 官网
- finl-learn社区
- 浅谈flink