无处不在的队列
队列定义
先进者先出

内存队列
顺序队列:使用数组实现的队列
链式队列:使用链表实现的队列
循环队列:避免顺序队列下队列满的数据搬移,动态计算tail和head指针
阻塞队列:入队满阻塞,出队空阻塞
并发队列:支持并发入队和并发出队
双端队列:对头队尾都支持入队和出队操作。既是生产者又是消费者
有界队列:队列大小固定
无界队列:队列大小无固定
优先队列:实际不是队列
应用场景
生产者-消费者(阻塞并发队列)
单消费者
- 解耦
- 异步
- 流水线模型:地铁调度模型
会议室系统的邮件发送
1 | /** |
多消费者(EventBus)
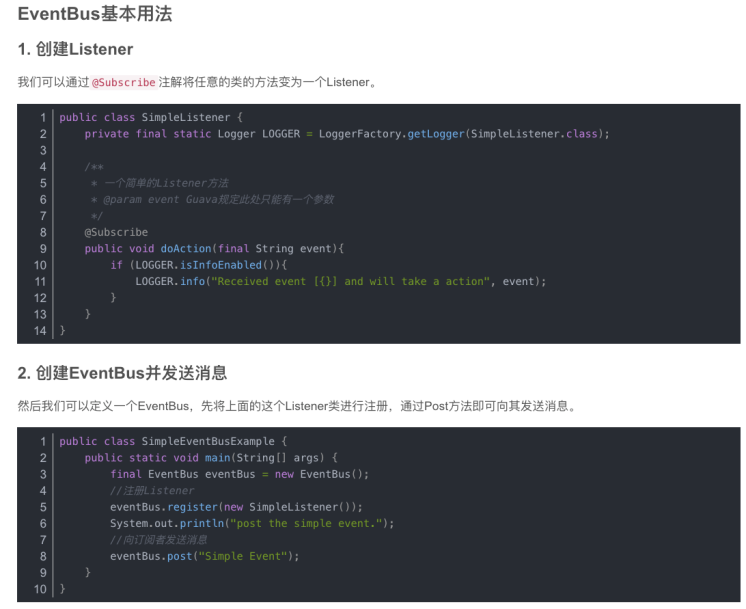
线程池(阻塞并发队列)
线程池创建
JDK其中阻塞队列:https://www.cnblogs.com/konck/p/9473677.html
1 | public ThreadPoolExecutor(int corePoolSize, // 核心线程数 |
队列在线程池中的应用:队列存放任务,利用队列实现线程复用,利用阻塞线程的超时来实现非核心线程的退出,以及核心线程和非核心线程的转换。下面为线程池中工作线程源码。
1 | private final class Worker implements Runnable { |
批量处理(阻塞并发队列)
先决:数据一致性不高,可靠性不高业务
例如数据库异步批量插入,日志批量写入ElasticSearch,Kafka批量发送模型,监控框架批量上报等
1 | public class MessageCache { |
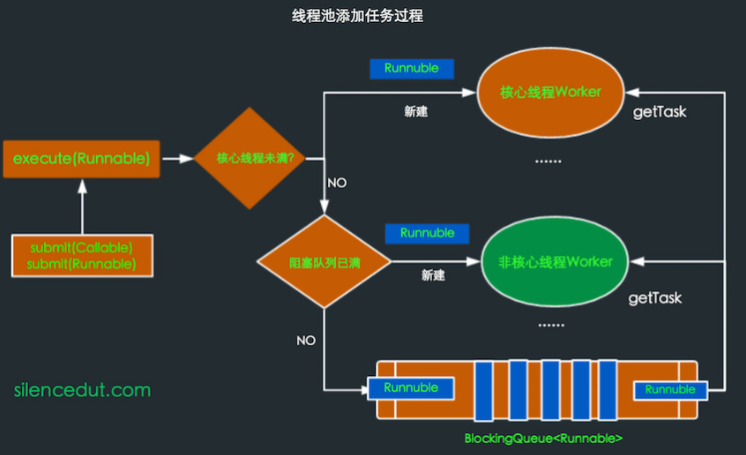
管程模型(阻塞并发队列 )
synchronized,wait-notify实现, AQS,ReentryLock&Condition等
工作密取(双端队列)
在生产者-消费者设计中,所有消费者共享一个工作队列,而在工作密取中,每个消费者都有各自的双端队列。如果一个消费者完成了自己双端队列中的全部工作,那么他就可以从其他消费者的双端队列末尾秘密的获取工作。具有更好的可伸缩性,这是因为工作者线程不会在单个共享的任务队列上发生竞争。
在大多数时候,他们都只是访问自己的双端队列,从而极大的减少了竞争。当工作者线程需要访问另一个队列时,它会从队列的尾部而不是头部获取工作,因此进一步降低了队列上的竞争。
Disruptor队列
https://blog.csdn.net/zhouzhenyong/article/details/81303011
Disruptor是一款高性能的有界阻塞并发内存队列,期初是英国外汇交易中心LMAX架构开发用来做交易的,单线程能支持600W QPS。目前很多知名框架都使用了Disruptor,比例Storm,Log4J2,HBase等。高性能的主要几个原因为:
- 内存分配合理,使用RingBuffer数据结构,数组元素在初始化时一次性全部创建,提升缓存命中率;对象循环利用,避免频繁GC。(空间局部性原则)
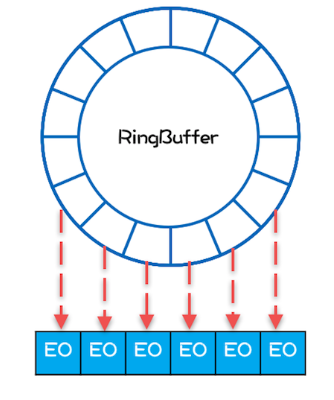
- 避免伪共享,提升缓存命中率;
- 采用无锁算法(写时拷贝),避免频繁加锁、解锁的性能损耗;
- 支持批量消费,消费者可以无锁方式消费多个消息
消息队列
业界产品:ActiveMQ,RabbitMQ,RocketMQ,Kafka,MetaMQ
应用场景
解耦,最终一致性,广播,削峰填谷,异步通知。
功能点
高可用,可靠投递,重复消息,顺序消息,push还是pull
Kafka
kafka是一个高可用,数据高可靠,高吞吐,低延迟的中心化消息队列
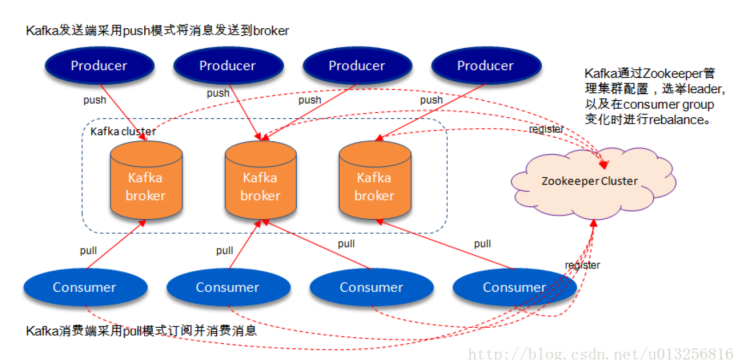
系统架构图
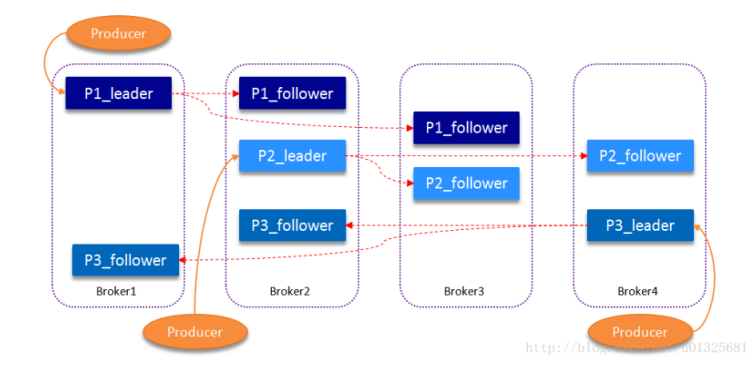
Partition多副本
文件存储
Kafka中消息是以topic进行分类的,生产者通过topic向Kafka broker发送消息,消费者通过topic读取数据。然而topic在物理层面又能以partition为分组,一个topic可以分成若干个partition,那么topic以及partition又是怎么存储的呢?partition还可以细分为segment,一个partition物理上由多个segment组成,那么这些segment又是什么呢?
发送模型
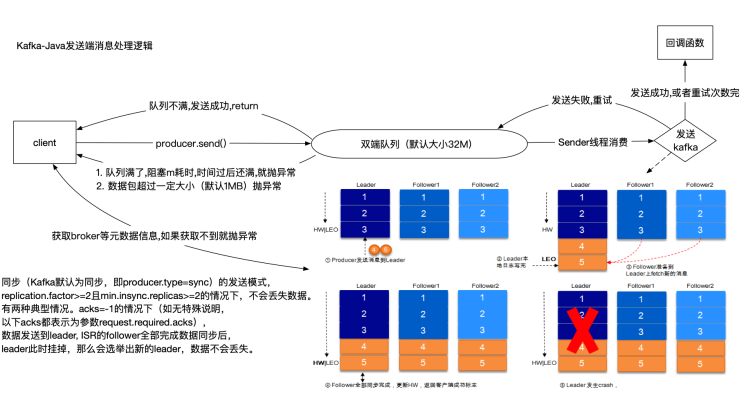
- 和kafka交互获取到broker的元数据信息(往哪个broker发),获取不到就抛出异常
- 判断消息包大小是否符合,默认为1MB,如果超过该大小则抛异常,修改配置需要和broker一起配合修改,具体看文章https://blog.csdn.net/hanjibing1990/article/details/51673540
- 往客户端内部的双端队列send消息,队列默认大小为32M,当大小不够时则会阻塞,阻塞时间可配,当阻塞时间过后则会抛出异常给客户端。
同时有一个Sender线程会实时批量拉取双端队列内消息往kafka集群发送。如果发送成功,则进入回调函数,返回RecordMetadate对象。如果发送失败,则进行重试,重试次数可配,当重试次数用完,则进入客户端定义的回调函数由客户端处理。
参数配置
ProducerConfig.ACKS_CONFIG
指定必须有多少个分区副本收到消息,生产者才会认为消息写入是成功的。程序中设置为-1
- ack=0:生产者不会等待任何来自服务器的响应。
如果当中出现问题,导致服务器没有收到消息,那么生产者无从得知,会造成消息丢失
由于生产者不需要等待服务器的响应所以可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量 - acks=1(默认值):只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应
如果消息无法到达Leader节点(例如Leader节点崩溃,新的Leader节点还没有被选举出来)生产者就会收到一个错误响应,为了避免数据丢失,生产者会重发消息
如果一个没有收到消息的节点成为新Leader,消息还是会丢失
此时的吞吐量主要取决于使用的是同步发送还是异步发送,吞吐量还受到发送中消息数量的限制,例如生产者在收到服务器响应之前可以发送多少个消息 - acks=-1:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应
这种模式是最安全的,可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群依然可以运行
延时比acks=1更高,因为要等待不止一个服务器节点接收消息
ProducerConfig.RETRIES_CONFIG
生产者从服务器收到临时性错误(如分区找不到Leader)时,retries参数决定了生产者可以重发消息的次数,程序中设置为 Integer.MAX
- 默认情况下,生产者会在每次重试之间等待100ms,控制参数为
retry.backoff.ms - 可以先测试一下恢复一个崩溃节点需要多少时间,假设为T,让生产者总的重试时间比T长,否着生产者会_过早地放弃重试_有些错误不是临时性错误,没办法通过重试来解决(例如消息太大),这个可以通过配置来改变producer,consumer以及broker可接受的的消息大小。(默认可接受的单个消息大小为1MB)一般情况下,因为生产者会自动进行重试。当出现不可重试的错误或者重试次数超过上限的情况时,现在的处理逻辑是打印错误信息,继续重试。client.id 任意字符串,服务器会用它来识别消息的来源,还可以用在日志和配额指标里。暂时没有配置 关于配置的相关介绍:http://www.aboutyun.com/thread-24147-1-1.html
ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION
Producer的另一个问题是消息的乱序问题。假设客户端代码依次执行下面的语句将两条消息发到相同的分区
1 | producer.send(record1); |
如果此时由于某些原因(比如瞬时的网络抖动)导致record1没有成功发送,同时Kafka又配置了重试机制和max.in.flight.requests.per.connection大于1(默认值是5,本来就是大于1的),那么重试record1成功后,record1在分区中就在record2之后,从而造成消息的乱序。
推荐配置
1 | // 只有当所有参与复制的节点**全部都收到消息时,生产者才会收到一个来自服务器的成功响应 |